前提知识
- 每个节点可以起一个或多个Executor。
- 每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
- 每个Task执行的结果就是生成了目标RDD的一个partiton。
Spark分区的概念
每个RDD/Dataframe被分成多个片,每个片被称作一个分区,每个分区的数值都在一个任务中进行,任务的个数也会由分区数决定。在我们对一个RDD/Dataframe时,其实是对每个分区上的数据进行操作。
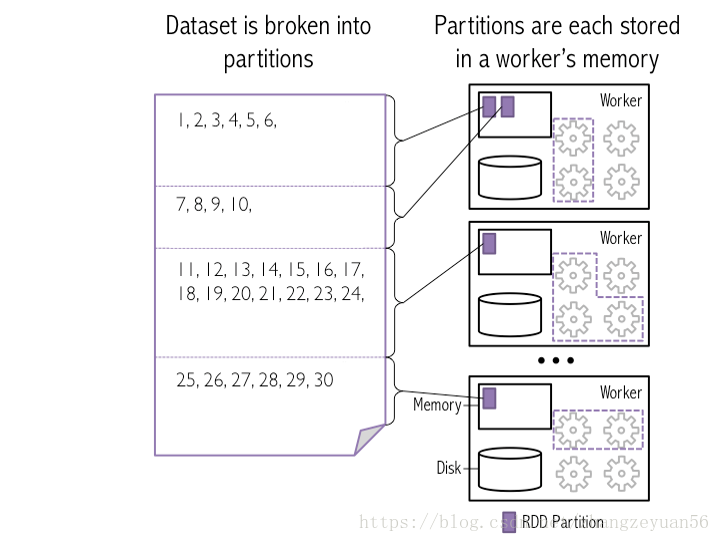 一个生动的例子: 比如的RDD有100个分区,那么计算的时候就会生成100个task,你的资源配置为10个计算节点,每个两2个核,同一时刻可以并行的task数目为20,计算这个RDD就需要5个轮次。
一个生动的例子: 比如的RDD有100个分区,那么计算的时候就会生成100个task,你的资源配置为10个计算节点,每个两2个核,同一时刻可以并行的task数目为20,计算这个RDD就需要5个轮次。
如果计算资源不变,你有101个task的话,就需要6个轮次,在最后一轮中,只有一个task在执行,其余核都在空转。
如果资源不变,你的RDD只有2个分区,那么同一时刻只有2个task运行,其余18个核空转,造成资源浪费。这就是在spark调优中,增大RDD分区数目,增大任务并行度的做法。
如何设置合理的分区数
- 默认分区数
- 本地模式:默认为本地机器的CPU数目,若设置了local[N],则默认为N
- Standalone或YARN:默认取集群中所有核心数目的总和,或者2,取二者的较大值。对于parallelize来说,没有在方法中的指定分区数,则默认为spark.default.parallelism,对于textFile来说,没有在方法中的指定分区数,则默认为min(defaultParallelism,2),而defaultParallelism对应的就是spark.default.parallelism。如果是从hdfs上面读取文件,其分区数为文件分片数(128MB/片)
- 分区设置多少合适
- 官方推荐的并行度是executor * cpu core的2-3倍。
窄依赖和宽依赖
- 窄依赖:每个父RDD的分区都至多被一个子RDD使用,比如map操作就是典型的窄依赖。
- 宽依赖:多个子RDD的分区依赖一个父RDD的分区。比如groupByKey都属于宽依赖。
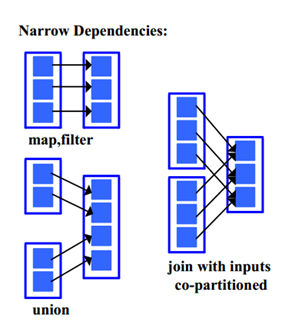
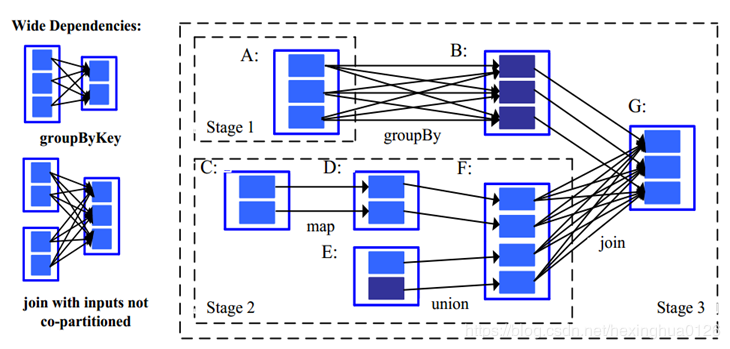
- 宽依赖的划分器:之前提到的join操作,如果是协同划分的话,两个父RDD之间, 父RDD与子RDD之间能形成一致的分区安排。即同一个Key保证被映射到同一个分区,这样就是窄依赖。如果不是协同划分,就会形成宽依赖。Spark提供两种划分器,HashPartitioner (哈希分区划分器),(RangePartitioner) 范围分区划分器. 需要注意的是分区划分器只存在于PairRDD中,普通非(K,V)类型的Partitioner为None。
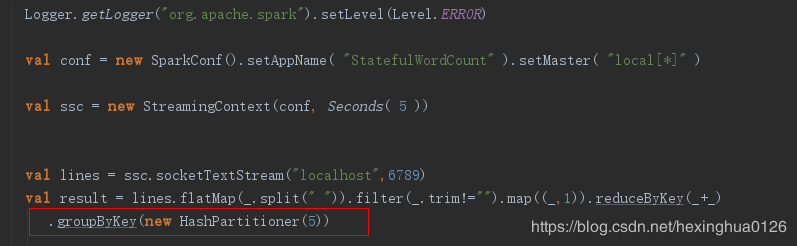 5表示groupByKey会有5个分区,以HashPartitioner划分为5个分区
5表示groupByKey会有5个分区,以HashPartitioner划分为5个分区