第五届阿里巴巴中间件比赛经验
目录
赛题官方介绍
虽然比赛已经结束一段时间了,但不妨记录一下这段中间件比赛的经历,感觉通过这个比赛还是收获到了不少的经验。
初赛
-
赛题介绍 - 《自适应负载均衡的设计实现》
题目是对Dubbo的负载均衡的实现,题目中给了一台Consumer和三台Provider,之后使用压测机对Consumer进行压测。要求Consumer每次自动选择一台Provider处理压测机的请求。

-
初赛排名 - 78/4095
-
实现方法
初赛最后比下来感觉就是考一个如何达到最佳分发状态。
首先为每台服务器记录他当前运行下的几个核心指标参数。这个参数我们记录了 运行成功数(success)、运行的数量(pending)、出错数量(error)、延迟的总时间(tt)。当然这里也是不断调出来的。
之后用filter处理每个Consumer到Provider的请求,请求时会为每次请求携带参数(开始时间),并未当前处理的数量(pending)+1),并通过onResponse()获取请求结束后的返回。返回值会判断处理时间(用返回的时间减去携带的开始时间),此次响应是否成功(有无Exception),此台机器配置的最大处理线程数(在provider处理时读取参数获得)。并记录到每台机器的状态上。
/** * @author daofeng.xjf * * 客户端过滤器 * 可选接口 * 用户可以在客户端拦截请求和响应,捕获 rpc 调用时产生、服务端返回的已知异常。 */ @Activate(group = Constants.CONSUMER) public class TestClientFilter implements Filter { @Override public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException { try{ ServersStatus.startRequest(invoker.getUrl().toIdentityString()); invocation.getAttachments().put("startTime",String.valueOf(System.currentTimeMillis())); Result result = invoker.invoke(invocation); return result; }catch (Exception e){ throw e; } } @Override public Result onResponse(Result result, Invoker<?> invoker, Invocation invocation) { boolean ifSuccess; if (result.hasException()||result.getValue() == null||result.getValue().equals("")){ ifSuccess=false; }else { ifSuccess=true; } int lastTime = (int)(System.currentTimeMillis()-Long.parseLong(invocation.getAttachments().get("startTime"))); int maxThread = Integer.parseInt(result.getAttachments().get("maxThread")); ServersStatus.endRequest(invoker.getUrl().toIdentityString(),ifSuccess,lastTime,maxThread); return result; } }@Activate(group = Constants.PROVIDER) public class TestServerFilter implements Filter { @Override public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException { try { Result result = invoker.invoke(invocation); // 在这里简单的读取了下最大线程数 result.getAttachments().put("maxThread", String.valueOf(invoker.getUrl().getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS))); return result; } catch (Exception e) { e.printStackTrace(); throw e; } } @Override public Result onResponse(Result result, Invoker<?> invoker, Invocation invocation) { return result; } }之后当每次Consumer需要去调用Provider时,便会遍历所有服务器,用以上几个参数去计算一个权重值,根据权重值的大小,选择一个权重值大的机器作为处理机器。
初赛之后用这种方法便拿到了一个稳稳进决赛的成绩,便没有再做调整了。
public class Server { public AtomicInteger success = new AtomicInteger(0); public AtomicInteger pending = new AtomicInteger(0); public int error = 0; public AtomicInteger tt = new AtomicInteger(0);//延迟总时间,除以成功数是每个成功的延迟时间 public int index; public int weight=0;//改为动态生成 public int initialWeight;//应该就不用了 public int maxThread=200; // public double generateWeight() { // double errorRate = (1 + success) / (double) (1 + error); // double delay = (1 + success) / (double) (1 + tt); // if (pending==0) return -1; // return errorRate * delay/((double) pending); // } public int generateThreadNum(){ int res =(int)(0.975*maxThread) - pending.get() - (tt.get()+1/(success.get()+1))/3; if(res<=0) res=1; return res; } }public class UserLoadBalance implements LoadBalance { public static ConcurrentMap<String, Server> servers = new ConcurrentHashMap(); // @Override // public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException { // int small = invokers.get(0).getUrl().getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS); // int medium = invokers.get(1).getUrl().getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS); // int large = invokers.get(2).getUrl().getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS); // int typeCount = count.getAndAdd(1); // typeCount%=6; // switch (typeCount){ // case 0: // return invokers.get(0); // case 1: // case 2: // return invokers.get(1); // default: // return invok // ers.get(2); // } //// return invokers.get(ThreadLocalRandom.current().nextInt(invokers.size())); // } @Override public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException { if (invokers == null || invokers.isEmpty()) { return null; } if (invokers.size() == 1) { return invokers.get(0); } if (servers.size() == 0) { synchronized (servers) { if (servers.size() == 0) { int count = 0; for (Invoker invoker : invokers) { Server temp = new Server(); temp.index=count; servers.put(invoker.getUrl().toIdentityString(), temp); count++; } } } } // double max = 0; int index = -1; // for (int i=0;i<invokers.size();i++){ // Server server = servers.get(invokers.get(i).getUrl().toIdentityString()); // double weight = server.generateWeight(); // if(weight>max){ // max=weight; // index=server.getIndex(); // } // if (weight==-1){//某个机器要求直接选它 // index=server.getIndex(); // break; // } // } int sum = 0; int maxScore=0; int[] threads = new int[invokers.size()]; for (int i = 0; i < invokers.size(); i++) { Server server = servers.get(invokers.get(i).getUrl().toIdentityString()); int restThread = server.generateThreadNum(); // sum += restThread; // threads[i] = sum; if(restThread>=maxScore){ index = i; maxScore = restThread; } } // Random random = new Random(); // int randomNum = random.nextInt(sum) + 1; // for (int i = 0; i < threads.length; i++) { // if (randomNum > threads[i]) continue; // else { // index = i; // break; // } // } if (index == -1) { index = ThreadLocalRandom.current().nextInt(invokers.size()); } return invokers.get(index); } // private int maxWeight() { // if(mediumWeight>=smallWeight&&mediumWeight>=largeWeight){ // return mediumWeight; // } else if(largeWeight>=mediumWeight&&largeWeight>=smallWeight){ // return largeWeight; // } else { // return smallWeight; // } // } // // /** // * 返回所有服务器的权重的最大公约数 // * // * @return // */ // private int serverGcd() { // int comDivisor = 0; // for (int i = 0; i < 2; i++) { // if (comDivisor == 0) { // comDivisor = gcd(servers.get(i).getWeight(), servers.get(i + 1).getWeight()); // } else { // comDivisor = gcd(comDivisor, servers.get(i + 1).getWeight()); // } // } // return comDivisor; // } // // /** // * 求两个数的最大公约数 // * // * @param num1 // * @param num2 // * @return // */ // private int gcd(int num1, int num2) { // BigInteger i1 = new BigInteger(String.valueOf(num1)); // BigInteger i2 = new BigInteger(String.valueOf(num2)); // return i1.gcd(i2).intValue(); // } } -
总结
初赛的目的就是为了进复赛,所以我们也用了最简单的方法即设计了一个简单的计算权重公式,根据权重的大小决定处理的机器。最后看来效果也还不错,在比较早的时间就达到了复赛的要求。
当然在得到了权重后,我们也尝试了三种不同的方式发送:
-
选权重最大的直接发
-
按权重轮询发
-
按权重随机发
但最后其实三种方式的得分差不了太多。
这里同样记录下6种常见的负载均衡方法:
- 轮询法
- 随机法
- 源地址哈希法(根据地址算哈希值,n使所有相同机器由相同机器处理)
- 加权轮询法(这次尝试了)
- 加权随机法(这次尝试了)
- 最小连接数法
-
复赛
-
复赛题目 - 实现一个进程内基于队列的消息持久化存储引擎
实现一个消息队列,这个消息队列可以实现发送、按条件查询和求平均值功能。
其中消息的内容是:
- t long型(8bytes) 时间,保证有序
- a long型(8bytes) 一个随机的数值,不保证有序
- msg byte[](34bytes)携带的数据
查找时根据t范围和a范围查找,需要也返回msg。求平均值只求t范围内的a的平均值。
数据量:20亿条/100GB
机器性能:Xmx4g -XX:MaxDirectMemorySize=2g 即内存4g,堆外内存2g(堆外可以放allcoateDirect)
-
复赛排名 - 33/200 不知道有多少提交数量
- 前提知识
- NIO(其实也就大概了解ByteBuffer用法即可)
- 实现方法
此次实现方法共有几轮变更,将分别记录。
-
第一次有分 - 8000+
数据量100GB,而内存只有4GB,自然不可能简单的将所有数据压入内存,便知道要将数据存储至硬盘中。
平常在用hadoop,便很自然的想到了内存中存储数据地址,硬盘中存储数据的方式(类似于hdfs)。
由此处理思想就很简单了,由于t有序,开始计算如何压缩t。
由于有20亿条数据 -> 如果全部存储t在内存中占据大小为:2000000000 * 8bytes = 16000000000bytes = 16GB 则内存中也不够放。所以最终决定了,将时间索引分块放入内存中,内存中只记录每块的时间头,这样内存中的占用大小就大大降低了,t和a每256MB(也尝试过别的大小,影响其实不是很大)作为一块,记录一次时间索引。存储数据时,每个线程分为两个文件存储。t和a作为一个文件,读取时读取前8bytes和后8bytes区分t和a。msg作为一个文件存储,每次读取34bytes。
在写入、读取和求平均值,均是多线程操作,但每个线程的写入、读取和求平均值也都是同一线程运行,所以对于每个线程只需要维护好自己的两个文件(写入和读取都存自己的两文件中写读)就可以了。
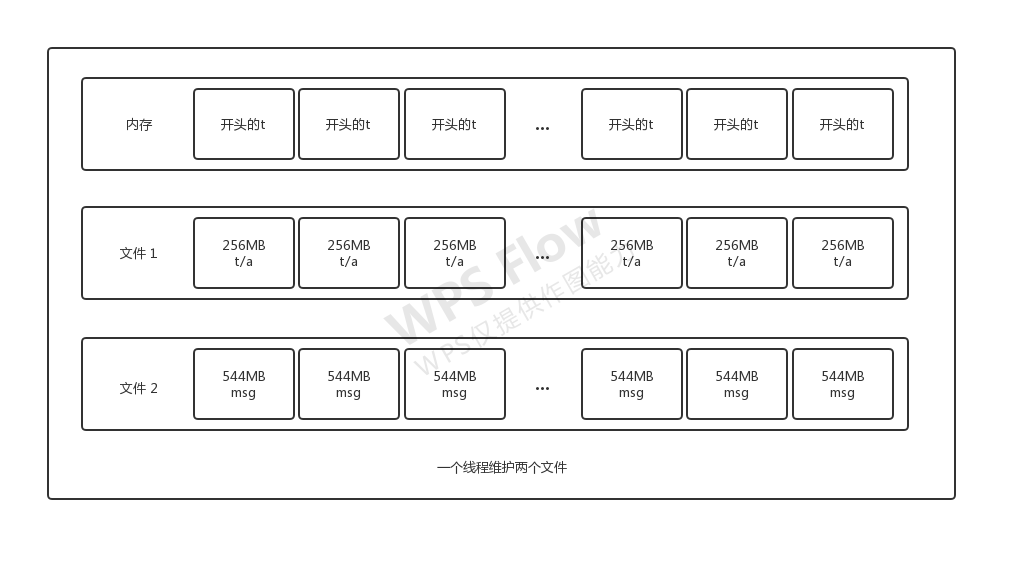
此时当需要查询一组数据时,便可以根据t用二分法查找到该组数据块的数据头(但注意这个数据头不是精准的,他只是找到了最小的有这个范围内的t的块,需要读取判断t的开始位置),之后找到该线程对应两个文件中对应块的位置,顺序读每块直到时间超过界限,再在读的过程中用a筛选一下就可以了。
对于求平均数部分也没有做任何的优化,与查询方法相同的方式读取全部的a出来再除以总数获得了平均值。
第一版最终得分在8000左右。
-
第二次分数大涨 - 12000+
整体方案与第一次的没有什么大区别,只不过每查询范围内t的时候,不在是只读出开头的地址,之后一块一块的去读,而是用二分法分别查出两个时间t的头和尾位置,直接分配头尾位置大小的ByteBuffer(但这个ByteBuffer可能不满,因为所找到的头尾不是精确的,还需要跟t判断找到首尾位置)。这样只需要一次读取就可以了
通过这种简单的方式,分数增长到了12000+。
-
第三次分数提高 15000+ 通过之前的架构已经很难再去有分数的增长了,所以必须要进行一些改动。思考了一番后,发现其实可以尝试将全部t也压入内存中,方式如下:
- 不再限制块的大小,转而可以让块大小自由定义。更改为限制每个块内的存储时间是在一个一个时间块(256s)内。
- 在内存中的t索引,变成了一个巨长的数组。其中将t以256s分块。在t的索引内记录的不在是确定的t,而是以一个base时间加上256s内的一个delta的delta。其中delta由一个byte表示,所有时间为256s。
这样通过把时间的long转换成了时间的delta即byte实现了压缩8倍的效果,最终将全部时间压缩到了内存中。
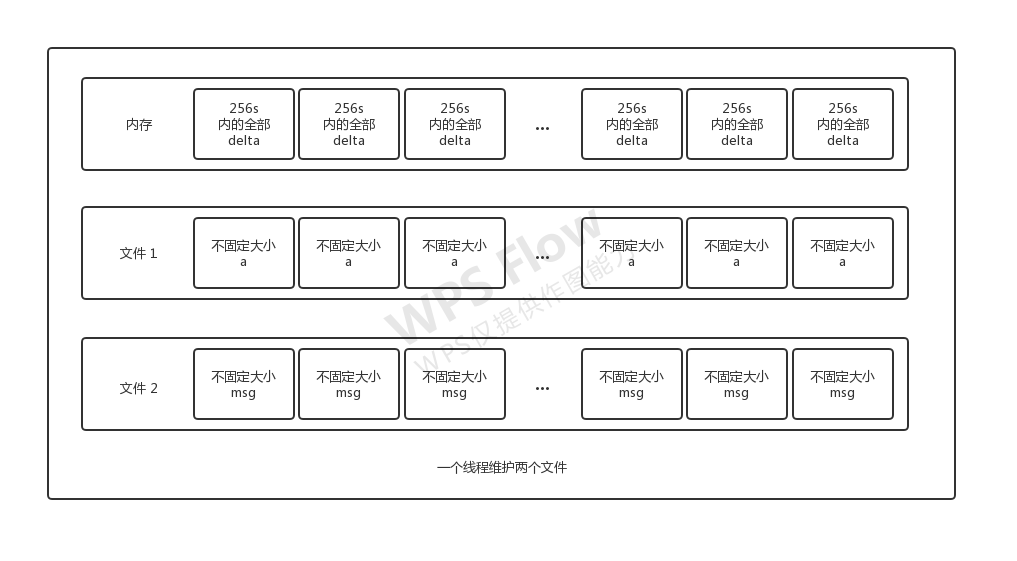
这样在读取时,通过时间可以算出delta的位置,进而计算出他所在的是第几个大块(即第几个256s)的第几个位置,从而读到a和msg的值。同时用这个方法,可以直接找到准确的t的开始位置和截止位置,无需对t做判断是否在范围内。把t的查找全部放入了内存中,大大增加了查询的速度。
-
第四次分数提高 17000+
因为全部t的索引占大小大概是2.5GB左右,内存还有1个GB多的剩余,便将a取了1GB放入内存中填满,也增块可能的a的查询速度。提高了1000多分左右吧。
其实在之后跟校内组的交流发现,他们比我们分数高,但其实他们都没有用第三次(全部压缩t)的方法,只是做了我们第二步的操作,并将a把内存填满。可能有的时候这种取巧的方法反而最后结果却最好
-
- 提高分时的小技巧
- 尽量在堆内存中的变量(如常量,别的类中的变量)需要多次使用时,先读取到栈内存中在使用,毕竟栈内存速度要快很多。这一举措涨了500分左右。
- 由于程序是一直在读取,可以提前分配出指定空间的ByteBuffer(可以比预计的大一些)。这样可以节省出每次都分配空间的时间。拿limit限制住大小就好了。这一举措涨了2000分。
-
总结
这是第一次参加比较大型的比赛,最后名次其实也还算不错。比赛经历过几次延期,延期之后我们也都开学了,就没有太多时间在搞比赛了。所以其实还有进一步提高排名的空间。例如在之后的听取大神报告时,了解到了他们不仅压缩了t,同时全量压缩了a,使得操作都在内存中完成,自然查询平均数的成绩高到爆炸。
对于复赛在后面的较量中主要比的就是压缩算法,谁压缩进的数据多,谁的最终效果就是好,而我们的压缩策略仍然比较简略,自然也就到这个排名位置了。同时有的时候也要多研究数据的规律,利用好数据的特性。例如这次比赛中t一定是有序且连续的这一点,便可以对t按大小分区分块,通过delta拿到位置。
有的时候复杂的方法也不一定是短时间内最有效的。在比赛接近尾声的时候,我们还在考虑压缩的方法。而最终出结果后发现,最简单的尽可能填满内存的方法成绩反而更简单有效。这在以后的比赛中的最后关头,可以借鉴,思考是否有简单有效的暴力方案解决问题。
- 代码