Spark中的Job、Stage、Task关系之前一直不是很清晰,今天研究了一下,主要参考文档
概览
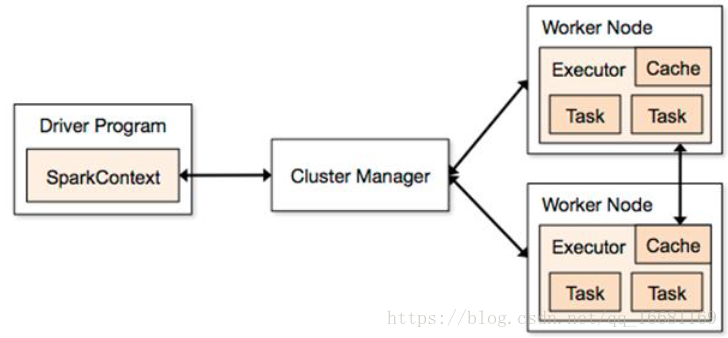
- spark应用提交后,经历了一系列的转换,最后成为task在每个节点上执行
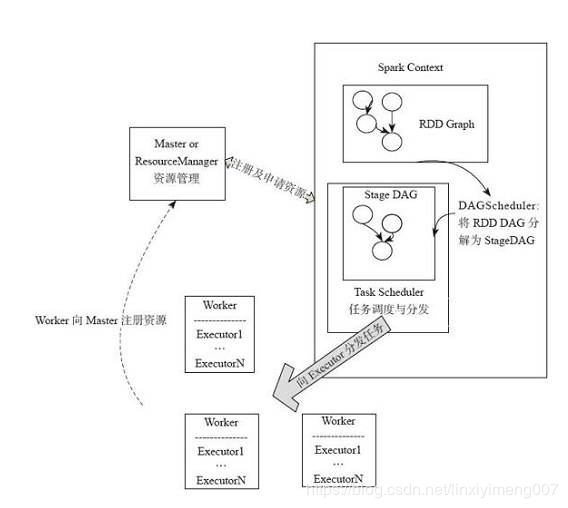
- RDD的Action算子触发Job的提交,生成RDD DAG
- 由DAGScheduler将RDD DAG转化为Stage DAG,每个Stage中产生相应的Task集合
- TaskScheduler将任务分发到Executor执行
- 每个任务对应相应的一个数据块,只用用户定义的函数处理数据块
这里拿一个简单的wordcount作为例子。代码如下:
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Author: fuhua
* @Date: 2019-06-19 14:45
*/
object WordCount {
def main(args: Array[String]) {
val conf = new SparkConf()
.setAppName("WordCount")
.setMaster("local[2]");
val sc = new SparkContext(conf)
val lines = sc.textFile("/Users/fuhua/Desktop/test.txt");
val words = lines.flatMap { line => line.split(" ")}
val pairs = words.map {word => (word, 1)}
val wordCount = pairs.reduceByKey(_ + _)
wordCount.foreach(wordCount => println(wordCount._1 + " 出现次数为: " + wordCount._2 + " times"))
println(wordCount.top(1).toSeq)
Thread.sleep(1000000000)
}
}
Job
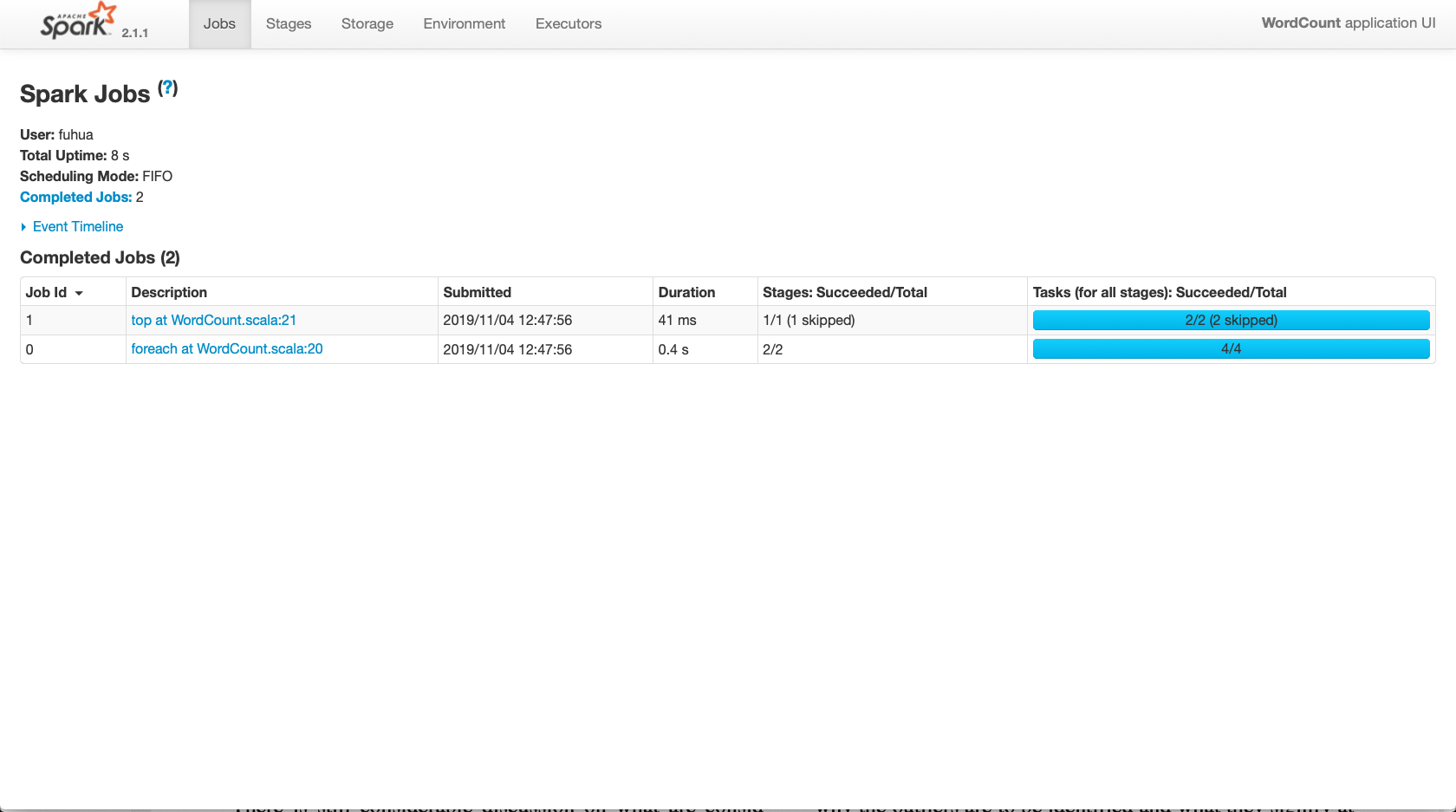
当要执行一个rdd action操作时,就会产生一个job,如在代码中的foreach和top操作,就有两个job。(即遇到action即生成一个新的Job)
注:spark的action操作和transformation操作:
- transformation: Transformation用于对RDD的创建,RDD只能使用Transformation创建,同时还提供大量操作方法,包括map,filter,groupBy,join等,RDD利用这些操作生成新的RDD,但是需要注意,无论多少次Transformation,在RDD中真正数据计算Action之前都不可能真正运行。
- action: Action是数据执行部分,其通过执行count,reduce,collect等方法真正执行数据的计算部分。实际上,RDD中所有的操作都是Lazy模式进行,运行在编译中不会立即计算最终结果,而是记住所有操作步骤和方法,只有显示的遇到启动命令才执行。这样做的好处在于大部分前期工作在Transformation时已经完成,当Action工作时,只需要利用全部自由完成业务的核心工作。
Stage
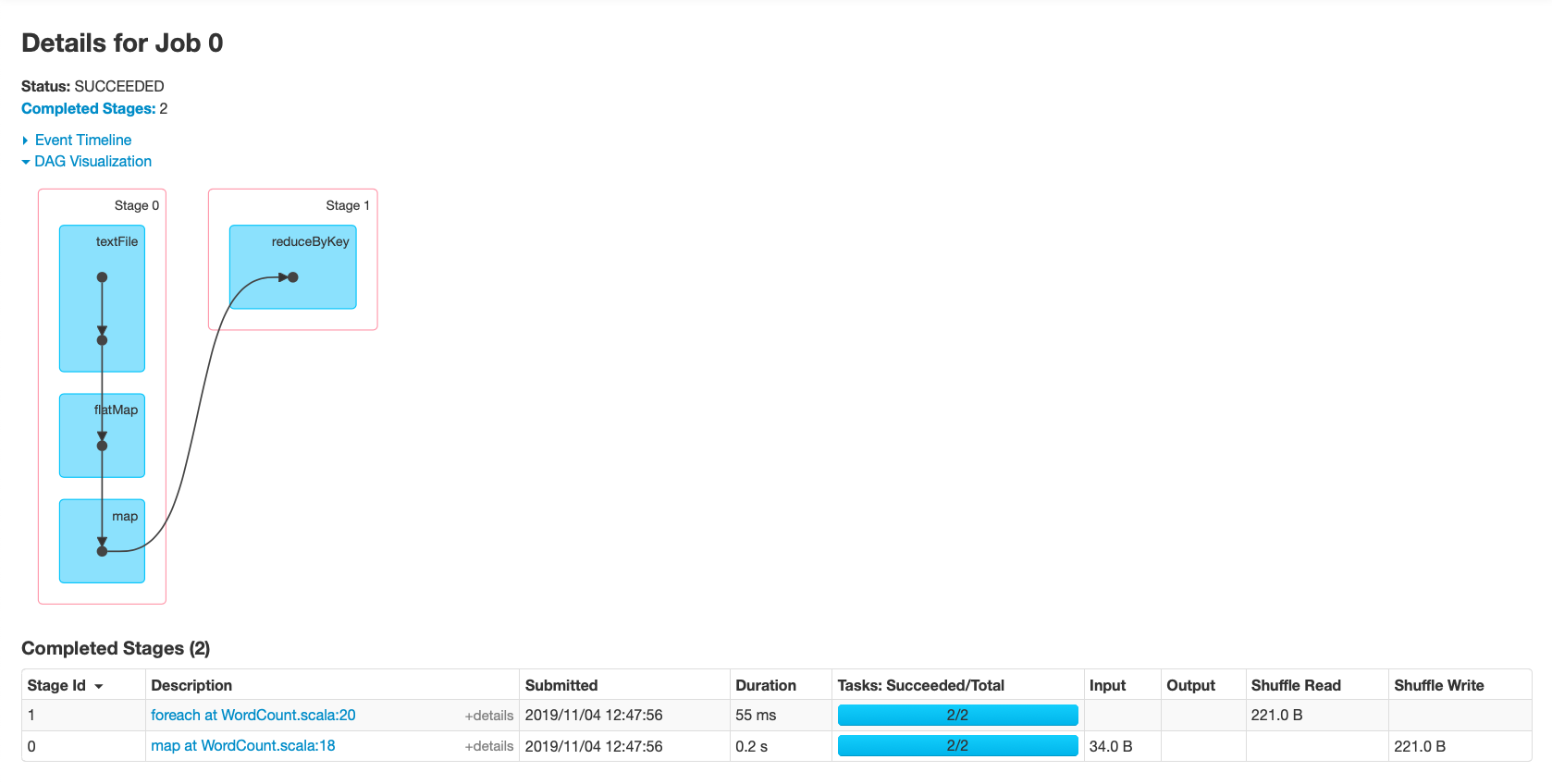
在DAGScheduler中,会将每个job划分成多个stage,它会从触发action操作的那个RDD开始往前推,首先会为最后一个RDD创建一个stage,然后往前倒推的时候,如果发现对某个RDD是宽依赖(执行了shuffle操作),那么就会将宽依赖的那个RDD创建一个新的stage。(即在job中从后往前倒退,遇到宽依赖新建stage)
注:窄依赖:
- 窄依赖:一般是transformation操作。父RDD和子RDD partition之间的关系是一对一的。一个分区只会对应一个分区操作,不会有shuffle的产生。父RDD的一个分区去到子RDD的一个分区中。如:map,flatMap
- 宽依赖:一般是action操作。父RDD与子RDD partition之间的关系是一对多的。一个分区可能会被之后的多个分区所用到,会有shuffle的产生。父RDD的一个分区去到子RDD的不同分区里面。如:reduceByKey 注:join操作即可能是宽依赖也可能是窄依赖,当要对RDD进行join操作时,如果RDD进行过重分区则为窄依赖,否则为宽依赖。
Task
task是stage下的一个任务执行单元,一般来说,一个rdd有多少个partition,就会有多少个task,因为每一个task只是处理一个partition上的数据。像我这次本地跑的,因为设定的是local[2]即两个CPU核心,所以是两个分区划分为两个task。(即stage的执行单元)
运行结果


同时也可以在运行日志中看到job、stage、task的日志过程:
先通过foreach拿到一个job,然后将其划分为两个stage(ResultStage的foreach和ShuffleMapStage的map),之后每个stage对应提交两个task(分区数量为2)
19/11/04 13:47:06 INFO SparkContext: Starting job: foreach at WordCount.scala:20
19/11/04 13:47:06 INFO DAGScheduler: Registering RDD 3 (map at WordCount.scala:18)
19/11/04 13:47:06 INFO DAGScheduler: Got job 0 (foreach at WordCount.scala:20) with 2 output partitions
19/11/04 13:47:06 INFO DAGScheduler: Final stage: ResultStage 1 (foreach at WordCount.scala:20)
19/11/04 13:47:06 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
19/11/04 13:47:06 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)
19/11/04 13:47:06 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount.scala:18), which has no missing parents
19/11/04 13:47:06 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.8 KB, free 2004.5 MB)
19/11/04 13:47:06 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.8 KB, free 2004.5 MB)
19/11/04 13:47:06 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 10.28.197.159:58402 (size: 2.8 KB, free: 2004.6 MB)
19/11/04 13:47:06 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:996
19/11/04 13:47:06 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount.scala:18)
19/11/04 13:47:06 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
19/11/04 13:47:06 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 5971 bytes)
19/11/04 13:47:06 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL, 5971 bytes)
19/11/04 13:47:06 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
19/11/04 13:47:06 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
19/11/04 13:47:06 INFO HadoopRDD: Input split: file:/Users/fuhua/Desktop/test.txt:0+5
19/11/04 13:47:06 INFO HadoopRDD: Input split: file:/Users/fuhua/Desktop/test.txt:5+5
19/11/04 13:47:07 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 1483 bytes result sent to driver
19/11/04 13:47:07 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1746 bytes result sent to driver
19/11/04 13:47:07 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 117 ms on localhost (executor driver) (1/2)
19/11/04 13:47:07 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 143 ms on localhost (executor driver) (2/2)
19/11/04 13:47:07 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
19/11/04 13:47:07 INFO DAGScheduler: ShuffleMapStage 0 (map at WordCount.scala:18) finished in 0.168 s
19/11/04 13:47:07 INFO DAGScheduler: looking for newly runnable stages
19/11/04 13:47:07 INFO DAGScheduler: running: Set()
19/11/04 13:47:07 INFO DAGScheduler: waiting: Set(ResultStage 1)
19/11/04 13:47:07 INFO DAGScheduler: failed: Set()
19/11/04 13:47:07 INFO DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount.scala:19), which has no missing parents
19/11/04 13:47:07 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 3.1 KB, free 2004.5 MB)
19/11/04 13:47:07 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1968.0 B, free 2004.4 MB)
19/11/04 13:47:07 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 10.28.197.159:58402 (size: 1968.0 B, free: 2004.6 MB)
19/11/04 13:47:07 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:996
19/11/04 13:47:07 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount.scala:19)
19/11/04 13:47:07 INFO TaskSchedulerImpl: Adding task set 1.0 with 2 tasks
19/11/04 13:47:07 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, localhost, executor driver, partition 0, ANY, 5750 bytes)
19/11/04 13:47:07 INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 3, localhost, executor driver, partition 1, ANY, 5750 bytes)
19/11/04 13:47:07 INFO Executor: Running task 1.0 in stage 1.0 (TID 3)
19/11/04 13:47:07 INFO Executor: Running task 0.0 in stage 1.0 (TID 2)
19/11/04 13:47:07 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 2 blocks
19/11/04 13:47:07 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 2 blocks
19/11/04 13:47:07 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 5 ms
19/11/04 13:47:07 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 5 ms