本文将从flink的执行架构入手,阐述flink的各个名词和组件之间的关系
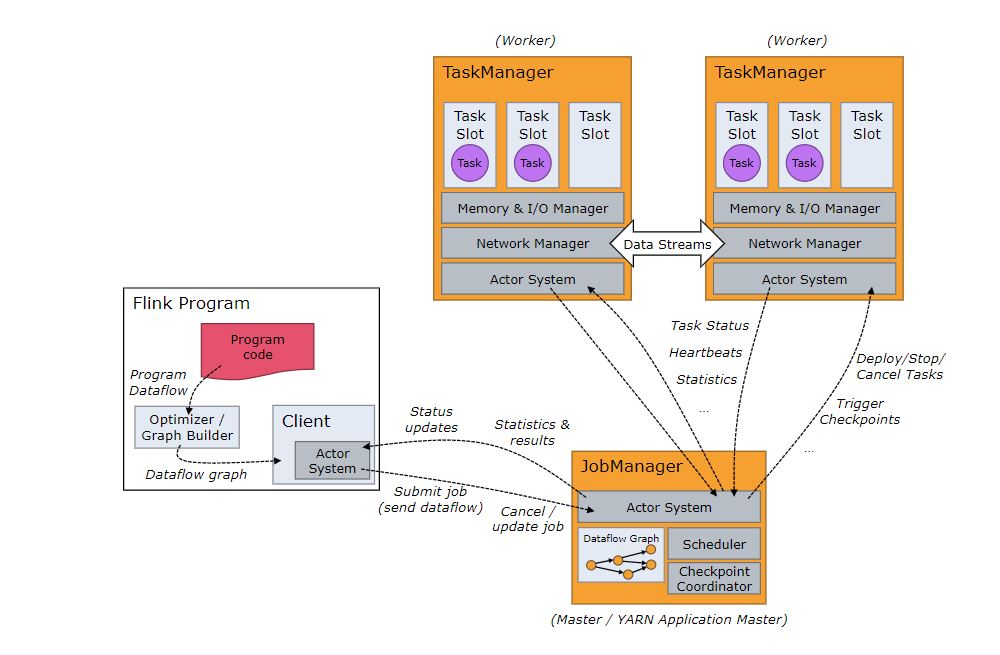
Job Managers、Task Managers、客户端(Clients)
Flink 运行时包含两类进程:
- JobManagers (也称为 masters)协调分布式计算。它们负责调度任务、协调 checkpoints、协调故障恢复等。 每个 Job 至少会有一个 JobManager。高可用部署下会有多个 JobManagers,其中一个作为 leader,其余处于 standby 状态。
- TaskManagers (也称为 workers)执行 dataflow 中的 tasks(准确来说是 subtasks ),并且缓存和交换数据 streams。 每个 Job 至少会有一个 TaskManager。 JobManagers 和 TaskManagers 有多种启动方式:直接在机器上启动(该集群称为 standalone cluster),在容器或资源管理框架,如 YARN 或 Mesos,中启动。TaskManagers 连接到 JobManagers,通知后者自己可用,然后开始接手被分配的工作。
客户端虽然不是运行时(runtime)和作业执行时的一部分,但它是被用作准备和提交 dataflow 到 JobManager 的。提交完成之后,客户端可以断开连接,也可以保持连接来接收进度报告。客户端既可以作为触发执行的 Java / Scala 程序的一部分,也可以在命令行进程中运行./bin/flink run …。
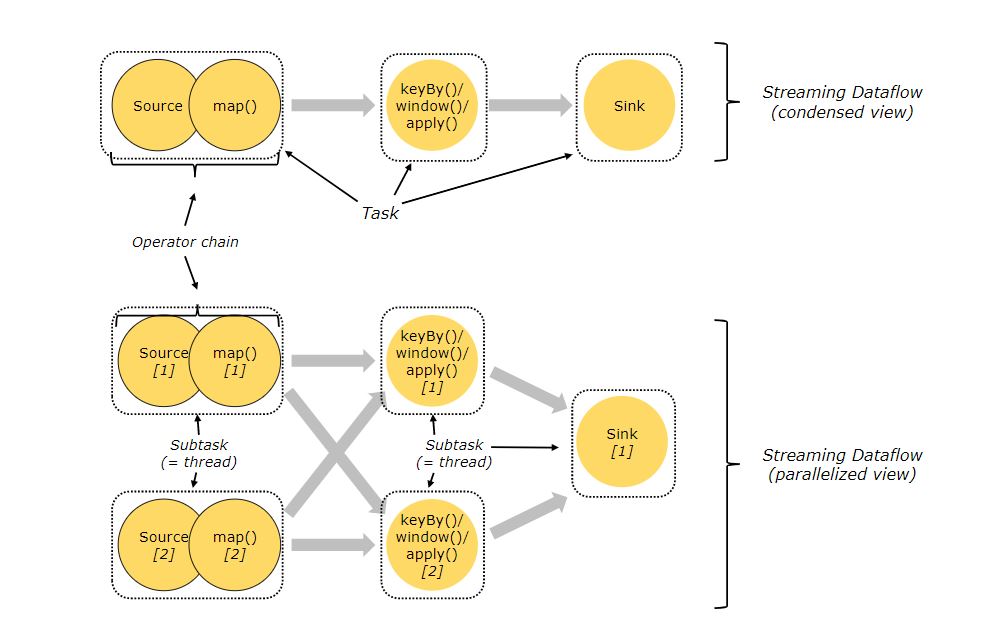
任务和算子链
分布式计算中,Flink 将算子(operator)的 subtask 链接(chain)成 task。每个 task 由一个线程执行。把算子链接成 tasks 能够减少线程间切换和缓冲的开销,在降低延迟的同时提高了整体吞吐量。
简单来说对流的每一个.后面的操作都可以看作是task,具体执行的时候有可能在多个task slot上执行,所以被拆成了subtask
下图的 dataflow 由五个 subtasks 执行,因此具有五个并行线程。
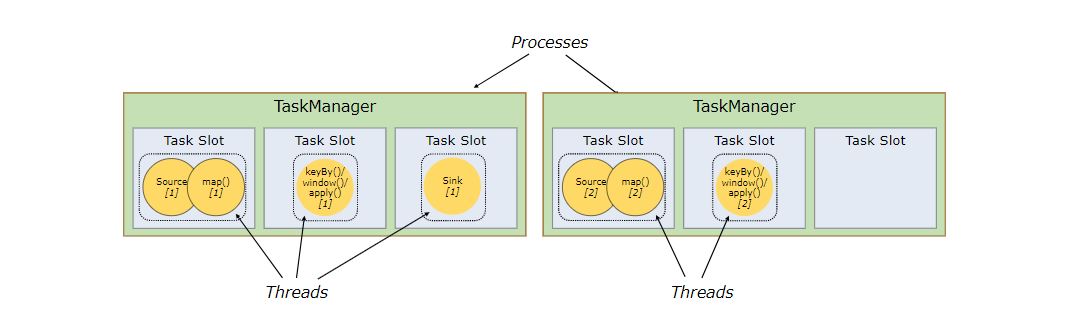
Task Slots 和资源
每个 worker(TaskManager)都是一个 JVM 进程,并且可以在不同的线程中执行一个或多个 subtasks。为了控制 worker 接收 task 的数量,worker 拥有所谓的 task slots (至少一个)。
每个 task slots 代表 TaskManager 的一份固定资源子集。例如,具有三个 slots 的 TaskManager 会将其管理的内存资源分成三等份给每个 slot。 划分资源意味着 subtask 之间不会竞争资源,但是也意味着它们只拥有固定的资源。注意这里并没有 CPU 隔离,当前 slots 之间只是划分任务的内存资源。
通过调整 slot 的数量,用户可以决定 subtasks 的隔离方式。每个 TaskManager 有一个 slot 意味着每组 task 在一个单独的 JVM 中运行(例如,在一个单独的容器中启动)。拥有多个 slots 意味着多个 subtasks 共享同一个 JVM。 Tasks 在同一个 JVM 中共享 TCP 连接(通过多路复用技术)和心跳信息(heartbeat messages)。它们还可能共享数据集和数据结构,从而降低每个 task 的开销。
默认情况下,Flink 允许 subtasks 共享 slots,即使它们是不同 tasks 的 subtasks,只要它们来自同一个 job。因此,一个 slot 可能会负责这个 job 的整个管道(pipeline)。允许 slot sharing 有两个好处:
-
Flink 集群需要与 job 中使用的最高并行度一样多的 slots。这样不需要计算作业总共包含多少个 tasks(具有不同并行度)。
-
更好的资源利用率。在没有 slot sharing 的情况下,简单的 subtasks(source/map())将会占用和复杂的 subtasks (window)一样多的资源。通过 slot sharing,将示例中的并行度从 2 增加到 6 可以充分利用 slot 的资源,同时确保繁重的 subtask 在 TaskManagers 之间公平地获取资源。
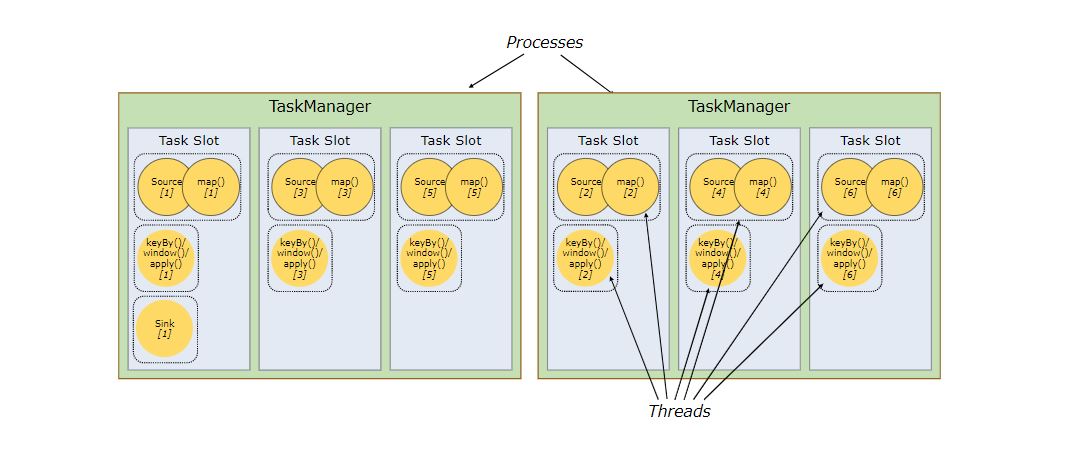
APIs 还包含了 resource group 机制,它可以用来防止不必要的 slot sharing。
根据经验,合理的 slots 数量应该和 CPU 核数相同。在使用超线程(hyper-threading)时,每个 slot 将会占用 2 个或更多的硬件线程上下文(hardware thread contexts)。
State Backends
key/values 索引存储的数据结构取决于 state backend 的选择。一类 state backend 将数据存储在内存的哈希映射中,另一类 state backend 使用 RocksDB 作为键/值存储。除了定义保存状态(state)的数据结构之外, state backend 还实现了获取键/值状态的时间点快照的逻辑,并将该快照存储为 checkpoint 的一部分。
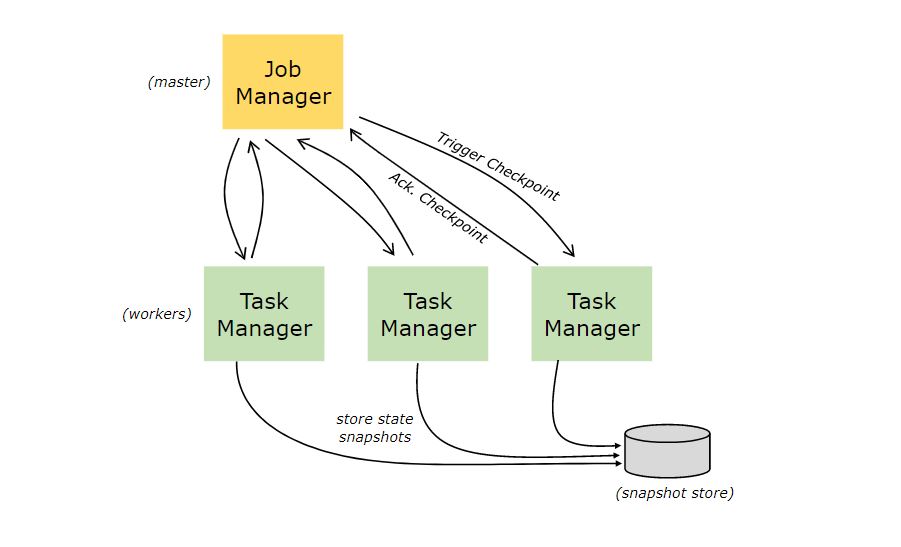
Savepoints
用 Data Stream API 编写的程序可以从 savepoint 继续执行。Savepoints 允许在不丢失任何状态的情况下升级程序和 Flink 集群。
Savepoints 是手动触发的 checkpoints,它依靠常规的 checkpoint 机制获取程序的快照并将其写入 state backend。在执行期间,程序会定期在 worker 节点上创建快照并生成 checkpoints。对于恢复,Flink 仅需要最后完成的 checkpoint,而一旦完成了新的 checkpoint,旧的就可以被丢弃。
Savepoints 类似于这些定期的 checkpoints,除了它们是由用户触发并且在新的 checkpoint 完成时不会自动过期。你可以通过命令行 或在取消一个 job 时通过 REST API 来创建 Savepoints。
词汇表
Flink Application Cluster
Flink Application Cluster 是一个专用的 Flink Cluster,它仅用于执行单个 Flink Job。Flink Cluster的生命周期与 Flink Job的生命周期绑定在一起。以前,Flink Application Cluster 也称为job mode的 Flink Cluster。和 Flink Session Cluster 作对比。
Flink Cluster
一般情况下,Flink 集群是由一个 Flink Master 和一个或多个 Flink TaskManager 进程组成的分布式系统。
Event
Event 是对应用程序建模的域的状态更改的声明。它可以同时为流或批处理应用程序的 input 和 output,也可以单独是 input 或者 output 中的一种。Event 是特殊类型的 Record。
ExecutionGraph
见 Physical Graph。
Function
Function 是由用户实现的,并封装了 Flink 程序的应用程序逻辑。大多数 Function 都由相应的 Operator 封装。
Instance
Instance 常用于描述运行时的特定类型(通常是 Operator 或者 Function)的一个具体实例。由于 Apache Flink 主要是用 Java 编写的,所以,这与 Java 中的 Instance 或 Object 的定义相对应。在 Apache Flink 的上下文中,parallel instance 也常用于强调同一 Operator 或者 Function 的多个 instance 以并行的方式运行。
Flink Job
Flink Job 代表运行时的 Flink 程序。Flink Job 可以提交到长时间运行的 Flink Session Cluster,也可以作为独立的 Flink Application Cluster 启动。
JobGraph
见 Logical Graph。
Flink JobManager
JobManager 是在 Flink Master 运行中的组件之一。JobManager 负责监督单个作业 Task 的执行。以前,整个 Flink Master 都叫做 JobManager。
Logical Graph
Logical Graph 是一种描述流处理程序的高阶逻辑有向图。节点是Operator,边代表输入/输出关系、数据流和数据集中的之一。
Managed State
Managed State 描述了已在框架中注册的应用程序的托管状态。对于托管状态,Apache Flink 会负责持久化和重伸缩等事宜。
Flink Master
Flink Master 是 Flink Cluster 的主节点。它包含三个不同的组件:Flink Resource Manager、Flink Dispatcher、运行每个 Flink Job 的 Flink JobManager。
Operator
Logical Graph 的节点。算子执行某种操作,该操作通常由 Function 执行。Source 和 Sink 是数据输入和数据输出的特殊算子。
Operator Chain
算子链由两个或多个连续的 Operator 组成,两者之间没有任何的重新分区。同一算子链内的算子可以彼此直接传递 record,而无需通过序列化或 Flink 的网络栈。
Partition
分区是整个数据流或数据集的独立子集。通过将每个 Record 分配给一个或多个分区,来把数据流或数据集划分为多个分区。在运行期间,Task 会消费数据流或数据集的分区。改变数据流或数据集分区方式的转换通常称为重分区。
Physical Graph
Physical graph 是一个在分布式运行时,把 Logical Graph 转换为可执行的结果。节点是 Task,边表示数据流或数据集的输入/输出关系或 partition。
Record
Record 是数据集或数据流的组成元素。Operator 和 Function接收 record 作为输入,并将 record 作为输出发出。
Flink Session Cluster
长时间运行的 Flink Cluster,它可以接受多个 Flink Job 的执行。此 Flink Cluster 的生命周期不受任何 Flink Job 生命周期的约束限制。以前,Flink Session Cluster 也称为 session mode 的 Flink Cluster,和 Flink Application Cluster 相对应。
State Backend 对于流处理程序,Flink Job 的 State Backend 决定了其 state 是如何存储在每个 TaskManager 上的( TaskManager 的 Java 堆栈或嵌入式 RocksDB),以及它在 checkpoint 时的写入位置( Flink Master 的 Java 堆或者 Filesystem)。
Sub-Task
Sub-Task 是负责处理数据流 Partition 的 Task。”Sub-Task”强调的是同一个 Operator 或者 Operator Chain 具有多个并行的 Task 。
Task
Task 是 Physical Graph 的节点。它是基本的工作单元,由 Flink 的 runtime 来执行。Task 正好封装了一个 Operator 或者 Operator Chain 的 parallel instance。
Flink TaskManager
TaskManager 是 Flink Cluster 的工作进程。Task 被调度到 TaskManager 上执行。TaskManager 相互通信,只为在后续的 Task 之间交换数据。
Transformation
Transformation 应用于一个或多个数据流或数据集,并产生一个或多个输出数据流或数据集。Transformation 可能会在每个记录的基础上更改数据流或数据集,但也可以只更改其分区或执行聚合。虽然 Operator 和 Function 是 Flink API 的“物理”部分,但 Transformation 只是一个 API 概念。具体来说,大多数(但不是全部)Transformation 是由某些 Operator 实现的。