又是一年过去了,距离上次写博客已经是一年多前的事情了。这一年也是经历了很多的事情,首先最大的变化就是我成家了,和媳妇领了证,然后在昌平买了房。工作上顺利入职了腾讯,现在也已经工作了一年多的时间了。
先简单说说正式工作这一年的自己的一些感受吧。
入职初期还是很幸福的,那会整体经济形势比较好,互联网的福利待遇很棒。入职腾讯的这个组呢也是正好在做转型。本来这个组是一个SRE组,当时入职的时候和总监聊,我明确表明我不想干SRE的工作,以至于,刚入职的时候,我们全组的职位都是运营开发,唯独我一个人是后台开发,整个大组的在进行一个运维上岸的转型工作,其实就是让运营的同学转为开发同学。说实话,大老板还是比较讲情谊的,没有把这些运维的同学全都裁了,重新招开发同学。因为转型,所以其实没什么项目,入职的头几个月是相当的轻松,基本上就没什么工作要干。相比于实习的字节和阿里,简直舒服到爆炸。头几个月呢,弄了一个流程引擎的项目,其实也是针对开源的流程引擎 flowable 进行了改造和封装。Flowable流程引擎可用于部署BPMN 2.0流程定义(用于定义流程的行业XML标准), 创建这些流程定义的流程实例,进行查询,访问运行中或历史的流程实例与相关数据,等等。Flowable 是基于 Java 的开源项目,因此对我而言轻车熟路了,这一段时间的技术成长主要还是一些前端技能的成长,由于前后端都得自己写,所以学习了VUE2和VUE3以及TypeScript。从研究生期间的js、jquery、ajax、structs2 到后来阿里的 umi + ant design + react 再到腾讯的 vue ts,我不得不感叹一下前端技术迭代之快,框架淘汰更新速度之快,以至于每次我写前端,基本上都要重新从头开始学一下时下最主流的框架。好在前端属于前期上手曲线低,能快速学习上手开发,所以学习成本并不是很高,加上之前前端的底子,开发也没啥难度。
当组织定位转型完之后,项目立项也定了,我所在的组主要负责故障管理和故障预防工作,说的更直白一些,就是负责搭建 Oncall 平台的。说实话自己是真没想到,在字节最深恶痛绝的就是 Oncall,没想到来了腾讯,会去负责搞这个 Oncall 的平台建设…虽然对这个也没多感兴趣,不过既来之则安之,在项目搭建初期,还是非常忙碌的,大概忙了两三个月吧,那一阵子全组的同学基本上周六周日都会去加班,周中的工作强度也比较大。虽然工作强度比较大,但是技术难度其实并不是很高,整个平台并没有太多的技术难点,因此心理压力其实还是比较小的,经历了字节那魔鬼训练之后,能力还是完全能cover住在腾讯的工作内容。在搭建 oncall 平台的过程中,技术成长比较平稳,主要是语言的一些变化,从一个java开发变成了go的开发。并且对后端开发过程中遇到的一些组件例如Kafka、Pulsar、MySQL、ES、Redis等更加熟练了,对分布式锁、分布式定时任务等常用的后端实现更熟练了。
在搭建 oncall 平台时,我主要负责了两个模块和一些后端的规范制定。
第一个是规则模块,说来也巧,研究生毕设就搞的规则引擎,来了腾讯又搞了一个规则引擎,不过实现的设计方案上区别还是比较大的,毕设采用的 flink + drools的设计方案,在腾讯采用了 Kafka + aviator 的设计方案。主要原因在于使用场景的不同,研究生毕设上游有单独的数据接入模块用的Kafka,规则引擎只需消费接入数据,并且规则能力要求较重,有多种个性化的规则配置需求,drools本身是个比较重的规则适用方案。腾讯这块的场景是,oncall 平台对接多个告警平台,告警平台采用webhook的形式将数据接入到oncall 平台,接入模块验证数据合法性后直接将输入放入Kafka,规则模块对接入的告警数据进行数据过滤、ETL、和数据分发,整体流程固定,aviator是一个表达式引擎,可以通过表达式引擎实现一个轻量化的规则引擎,相比于drools更符合腾讯的业务场景。通过规则引擎,目前oncall 平台日均接入告警量超1w+,通过规则引擎过滤+聚合,减少了90%的告警量,帮助业务团队更加直观的定位到问题所在,缩短MTTR。
第二个模块是升级策略模块,升级策略支持配置多步的升级通知,每一步骤支持配置一个时间,例如2分钟后微信通知我,如果我还没接单,10分钟后电话通知我,还没接单,15分钟后给我leader打电话,类似于这样的场景。其实现本质是实现一个延迟队列。由于项目上线时间要求紧,第一版通过轮询DB的方式实现了一版,由于轮询DB通知延迟较高且对数据库有不必要的查询压力,因此第二版采用了pulsar延迟队列的实现。对比当前的一些延迟队列:
| 方案 | 优点 | 缺点 |
| 定时任务轮询DB |
|
|
| 基于Redis的Zset延时队列 |
|
|
| 基于Redis的过期回调 |
|
|
| 基于时间轮TimeWheel实现 |
|
|
| JDK的DelayQueue |
|
|
| Kafka |
|
|
| RabbitMQ |
|
|
| Pulsar |
|
|
| 其他MQ | 开源的NSQ、RocketMQ和ActiveMQ也都内置了延迟消息的处理能力。虽然每个MQ项目的使用和实现方式不同,但核心实现思路都一样:Producer将一个延迟消息发送到某个Topic中,Broker将延迟消息放到临时存储进行暂存,延迟跟踪服务会检查消息是否到期,将到期的消息进行投递。 |
规范上,定义了前后端交互格式定义,划分后端代码层级,trpc go的使用规范,后端rpc交互的规范等。让后端的代码风格统一,层级合理。顺道一提,在腾讯参加了readability的考试,其实也就是代码设计与规范的考试,这个考试的通过率只有百分之十,参加的第一期考试,从1000位腾讯同事中脱颖而出,获得了前十的好成绩(可能也是因此获得了一次优秀绩效哈哈哈)。
在oncall 平台搭建的差不多后,我开始去做故障预防的工作。这一块的工作的确是比较有新意和挑战性的,对个人能力的成长帮助较大。说是故障预防,其实是搞演习平台或者故障注入的,提到故障注入,其实就是做混沌工程了。最一开始听到混沌工程的时候,觉得挺高级的,所以一下子就有了兴趣。混沌工程的官方定义:混沌工程(Chaos Engineering)是通过主动向系统中引入软件或 硬件的异常状态(扰动),制造故障场景并根据系统在各种压力下的 行为表现确定优化策略的一种系统稳定性保障手段。这一块目前业界有两个比较火的方案,一个是chaos blade (阿里)一个是 chaos mesh (PingCAP)(CNCF,Cloud Native Computing Foundation 项目)。
针对这两个项目的对比,网上已经有很多很详细的分析帖子了,我这里就不再过多赘述了,可参考 chaosblade和chaos-mesh作为生产测试标准,哪个更适合2020年的团队云原生技术规划? 简单说chaosblade 更像是一套用来管理具体 binary 的执行框架,各类故障注入是用脚本单独实现,由 chaosblade 调用执行,只能用来对单个物理节点进行错误注入。优点是提供的功比较多并且重点对于 JVM 的应用会更加友好。缺点对于多节点的集群来说就比较难用并且对 K8s 的错误注入局限在 patch 注入容器的方式,并不会去考虑具体的 chaos 的范围管理、生命周期管理以及应用的表现,只是负责去注入错误, 并不是云原生的理念。而chaos mesh All-in K8s,使用 K8s 原生的 API 和惯例,设计也是基于云原生的理念设计的。在目前整个云原生的大背景下,并实际使用对比chaos blade和 chaos mesh后,决定采用 chaos mesh作为我们混沌工程搭建的底层基架。
首先,在通过 CVM 自建 K8S 集群,在自建集群上部署了 ChaosMesh 服务,验证社区的各项混沌注入能力可用。 之后基于 ChaosMesh 进行二次开发,通过 Controller实现 K8S CRD 解析与任务调度,新增 selector 支持腾讯各平台各类型的节点选择。通过 K8S Operator 支持混沌实验的编排。针对历史的混沌平台进行了架构升级:
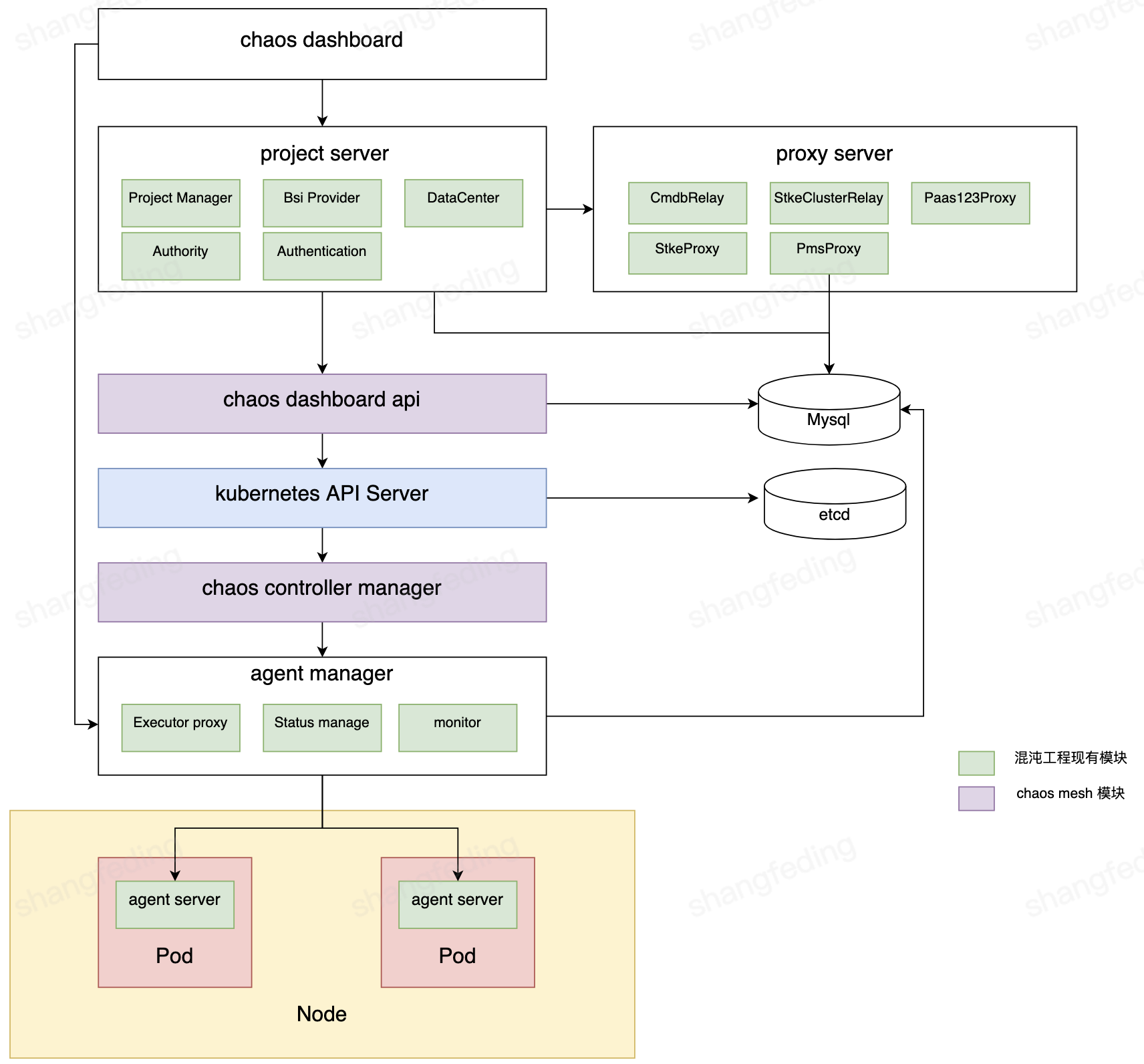
| 模块名 | 模块职责 |
| chaoa dashboard | 前端模块 |
| project server |
|
| proxy server |
|
| chaos dashboard api |
|
| chaos controller manager |
|
| agent manager |
|
| agent server |
|
以上基本就是在腾讯前大半年的工作内容,之后互联网寒冬,裁员潮就来了。故障预防项目直接夭折,小组内多人“毕业”。降本增效逐渐成为主题。在这样的大环境下,只能安安稳稳的狗住了。希望经济形势能好转,寒冬能早日离去吧。