实时决策引擎
近年来,随着网络技术的高速发展和数据量的爆发增长,对数据的实时规则判定、处理和决策变成了许多实时业务的基本需求。实时营销、实时推荐和实时风控等系统成为了许多互联网和金融企业的业务需求。由于业务不断发展,规则的复杂化和数量不断攀升,加之数据量的增长,基于人工或传统的数据分析处理引擎不能很好的满足业务实时性和业务变化导致的灵活更改规则的需要,一个可以灵活可配海量规则并给出实时反馈的决策引擎成为企业的重要需求。
在面向实时性业务时,需要将实时数据分类并分发到针对此数据构建的规则网进行匹配计算给出及时的决策反馈,在此流程中分发的策略,规则网的构建和划分,触发结果的消费方式,均会影响决策引擎的执行效率。搭建能够高效处理海量规则并实时决策的决策引擎已成为增强企业竞争力的必然选择。
针对这种情况,我的研究生毕业设计课题,旨在设计并实现一个处理流式数据并支持海量规则的决策引擎。该决策引擎可以对实时的流式数据进行计算和规则匹配,并且支持多种形式的决策动作,如风控告警,实时推荐等。并且在规则方面支持海量规则的接入,支持对规则网络的划分和聚合,并且规则可配置可修改,以满足对业务变化的支持。在数据方面,提供统一的数据格式接入方式,并通过流式框架对不同吞吐量的数据进行资源的分配和调度,使流式数据可以在分布式系统上合理的分发与高效的处理。在决策执行方式上提供多样化接口,为风险控制提供告警接口,为实时推荐提供推荐内容的输出与落盘。
在技术路线选择的时候。首先选择了近年来非常火爆的流式处理框架Flink。关于规则匹配算法选择了最通用性能最好的RETE算法,并用apache开源RETE算法实现工程Drools作为项目支持。数据来源接入使用Kafka。
总体架构
项目从开始到现在,前前后后经历了很多次的大大小小的修改,此处记录一下自己从项目构建到优化的一些思路。
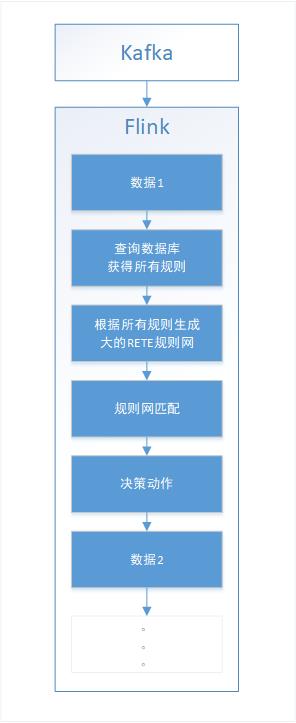
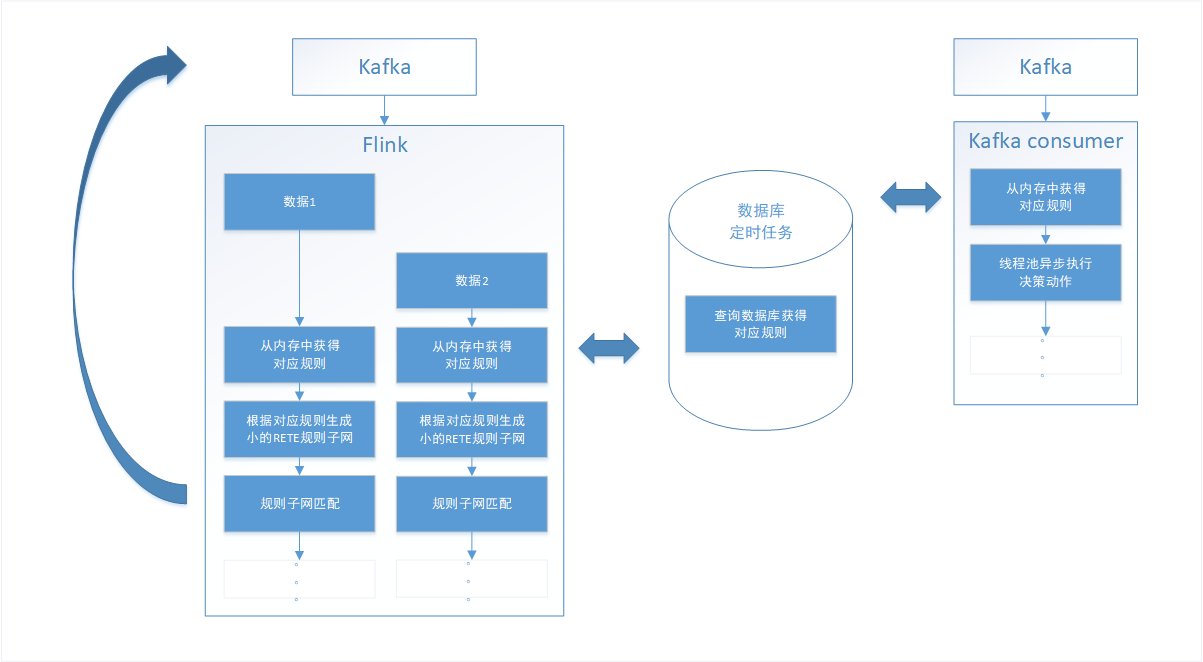
在代码开始的第一阶段,主要为了验证技术路线的可行性,确认Flink连接Kafka,并在Flink内部集成drools的可行性,没有做任何的性能指标考量,只为了能快速产出一个可运行可展示的系统。或者说此阶段为技术路线验证阶段。架构如上,Flink读取Kafka的指定topic,获得流数据,为了满足规则的可编辑性,将规则放入MySQL数据库中,每条数据来的时候,查询数据库获得所有规则。使用Drools将读取的所有规则构建RETE规则网,数据在规则网内进行匹配,如果触发,执行数据库中定义的决策语句,决策动作完成之后,接收下一条数据。
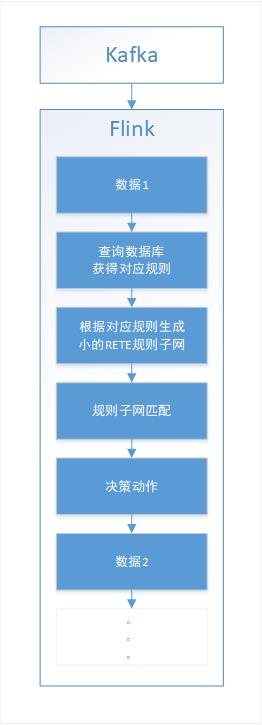
在第一阶段验证成功之后,开始思考此决策引擎需要满足的特性,首先是需要支持海量规则,在技术论证阶段将所有规则读入的方式必然是不合理的,因为并不是这个topic会用到所有的规则,因此在第二阶段我引入了rule set的概念,将topic和rule set进行对应(有可能是多对一的关系),将原来的所有规则划分成了多个rule set,在数据到达时,只需去数据库中加载和此topic相关的rule set并构建规则子网即可。使决策引擎对海量规则提供了一定的支持。总结:flink和kafka满足了实时的特性,avro满足了数据格式的统一性接入,drools满足RETE规则网匹配算法,数据库和rule set提供对海量规则和可编辑性的支持。
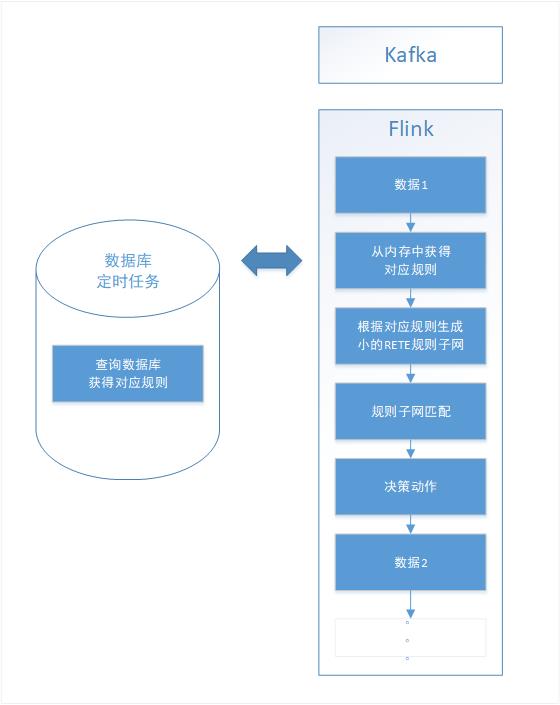
在第二阶段满足了决策引擎的基本特性之后,开始逐步考虑决策引擎的优化问题。首先我第一个想到的是与数据库的交互问题,在原架构中,每一条数据都需要和db进行一次接连交互,在数据量吞吐量很大的时候,mysql的连接数将变得不可控,对数据库的压力较大,并且影响决策引擎的效率。考虑到业务规则更改的频率并不一定很高,每次去数据库取规则获得最新规则并不是必须的,因此,将规则内容获取模块抽离,此模块将定时获得最新规则,并将新的规则写入内存,这样当数据来的时候,只需使用内存中的规则即可。规则的刷新时间可根据业务需求进行动态配置。在我的项目中,我设置为1分钟读取一次新的数据并写入内存。
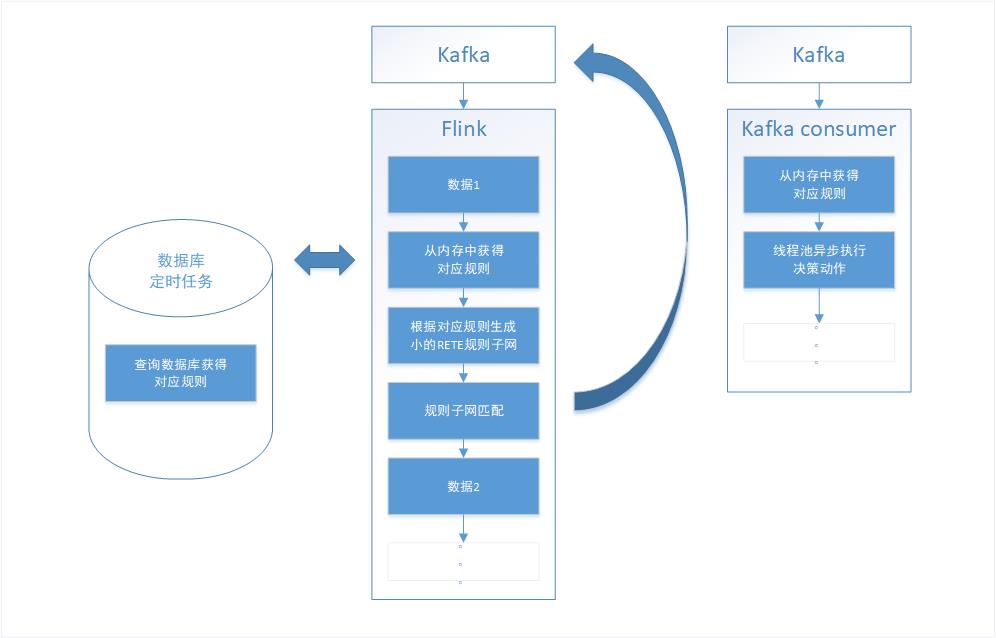
在解决了数据库的问题之后,由于在做项目的最初阶段,导师先没让我过多的考虑决策动作的执行,在第四阶段的时候,我开始思考决策动作可能是什么样子的,例如,风险控制可能是以短信或者邮件的方式对触发规则的内容进行告警,实时推荐的话,决策动作有可能是输出一个推荐内容或者将推荐内容落盘再呈现给用户。在上述几个场景中,第二条到来的数据都需要等待第一条数据的执行结束才能处理,由于决策动作的多样化,决策动作的执行时间不可控,有可能过长导致数据阻塞。再回首看Flink官网,一般流式处理结果会返回给流,因此我决定将规则网匹配成功的规则id返还给kafka,并考虑到决策动作的分布式执行(参加Flink Asia大会得到的灵感),将决策动作分发给不同的Kafka topic,再由业务种类的不同去提供相应的Kafka consumer执行方法。
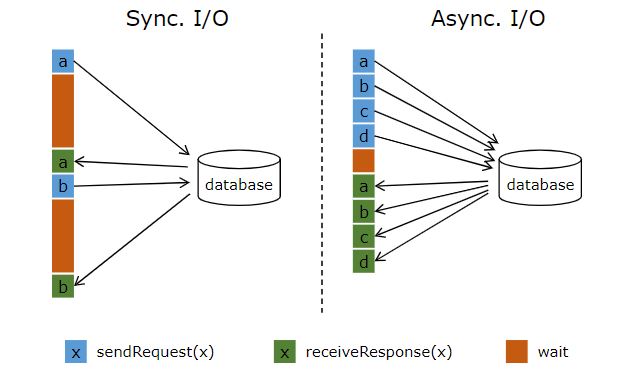
原来的数据都是同步执行,第二条到达的必须等第一条规则匹配完成后才能进行匹配,我开始思考flink是否可以将处理逻辑改为异步执行,然后在官网发现了Asynchronous I/O Operations,附上官网的介绍图
从第五阶段开始,逐步开始关注相应的性能指标,并进行了相应的测试,测试环境均为单机环境,第三阶段处理1w条kafka数据,耗时4.3分钟。第五阶段代码测试过程中一开始忘记加数据库缓存1分钟内数据,频繁的mysql读取,1w条数据耗时6.8分钟,看来每条数据都去请求mysql对性能的影响的确很大。测试后加入了数据库缓存,在异步处理并将决策动作分布式执行后,1w条数据用时3.7分钟,第五阶段比第三阶段的处理速度提高了17个百分点。测试过程中决策动作模拟的邮件告警,如果决策动作耗时更长的话,相较于第三阶段,处理速度提升会更高。
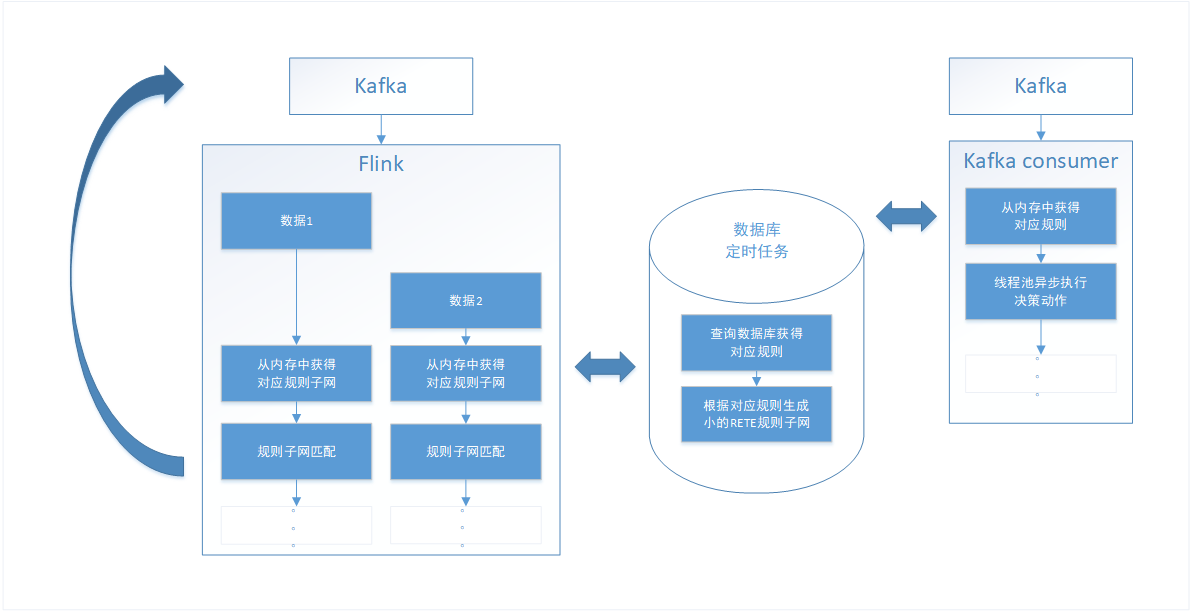
偶然间有一天我想到,现在每来一条数据其实都重新构建了一遍RETE规则子网,但其实用来构建规则网的规则1分钟才刷新一次,那为何要频繁的构建规则网呢?这样的设计显然不合理,应该把规则网的构建也放入到数据库定时任务模块之中去,只有当一个rule set内规则发生变化的时候,才需要将规则子网重新构建并存入内存,这样的设计才更合理。并且这样使得没有更改的rule set规则网并不需要变更,换言之,并不是数据库中一条规则的变动就需要更改整个RETE规则网络。通过把构建规则网的过程和数据库刷新频率保持一致,处理效率取得了意想不到的巨大提升,在同样的测试环境下,处理1w条kafka数据仅用时57秒,比第五阶段快了整整4倍!也由此可见,构建RETE规则网是一个十分耗时的过程。
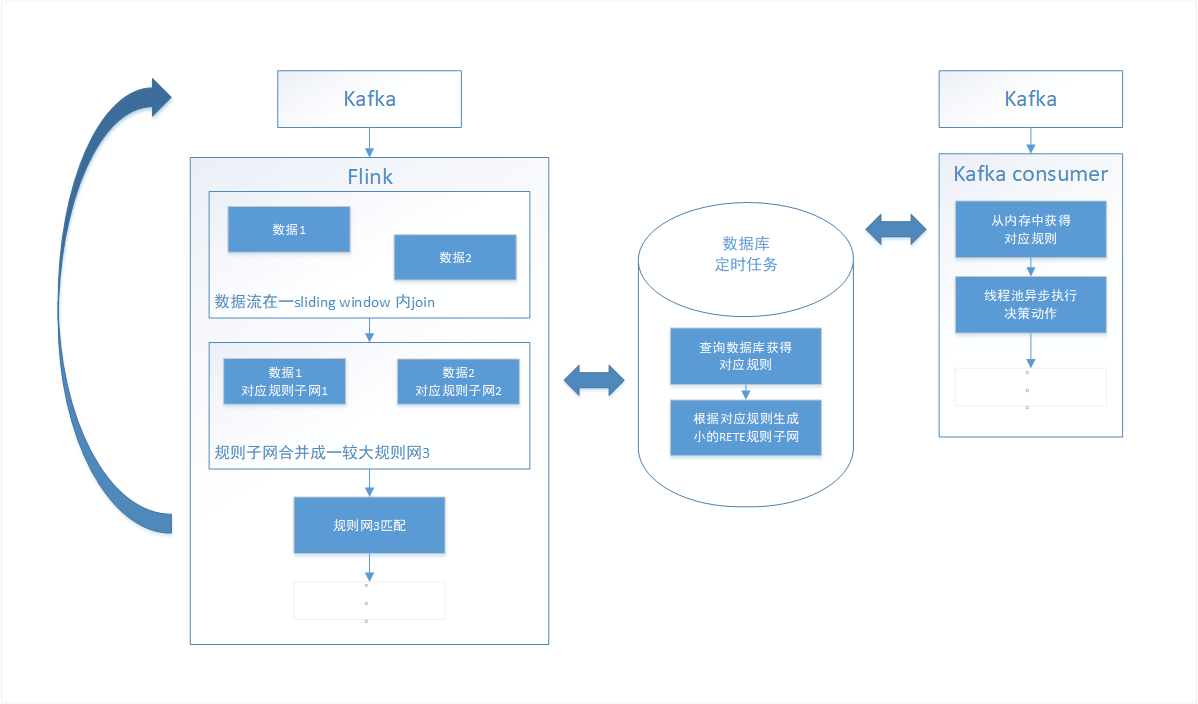
在实际应用场景中,我们有的时候根据一条数据流并不能分析得到我们想要的结果或者数据。例如一个大数据平台,一个流是负责监控硬盘剩余量的,另外一个流是负责监控大数据平台I/O的,这两个流都有自己的监控规则,例如硬盘剩余量小于1T给告警,写入速度超过1G/s给出告警,单基于这两个流,和这两个规则,我们无法得知硬盘资源将在多久以后耗尽,只是将两个流中数据合并分析,用大数据平台剩余硬盘空间除以大数据平台数据写入速率,才能得知硬盘将在多久以后写满,并根据计算所得天数进行规则匹配进行告警。在上述场景中,决策引擎就需要对流中数据和规则进行聚合操作,利用flink的join算子,我实现了这一功能。
最后附上github地址 GitHub