项目实时决策引擎需要用到“大数据计算框架”,更通俗一些说就是选用一款适合的流处理或者批处理框架,所以调研了几款比较流行的框架,总结他们的特点和区别。之前在我们组内的Free分享中写的博客,现在转回自己的个人博客。
概况
仅批处理框架:
Apache Hadoop
仅流处理框架:
Apache Storm
Apache Samza
Kafka Streams
混合框架:
Apache Spark
Apache Flink
Hadoop
提起大数据,第一个想起的肯定是Hadoop,因为Hadoop是目前世界上应用最广泛的大数据工具,他凭借极高的容错率和极低的硬件价格,在大数据市场上风生水起。Hadoop还是第一个在开源社区上引发高度关注的批处理框架,他提出的Map和Reduce的计算模式简洁而优雅。迄今为止,Hadoop已经成为了一个广阔的生态圈,实现了大量算法和组件。由于Hadoop的计算任务需要在集群的多个节点上多次读写,因此在速度上会稍显劣势,但是其吞吐量也同样是其他框架所不能匹敌的。
Apache Storm
Apache Storm是一种侧重于极低延迟的流处理框架,也许是要求近实时处理的工作负载的最佳选择。该技术可处理非常大量的数据,通过比其他解决方案更低的延迟提供结果。具体的架构原理推荐阅读博客,Storm原理1,Storm原理2
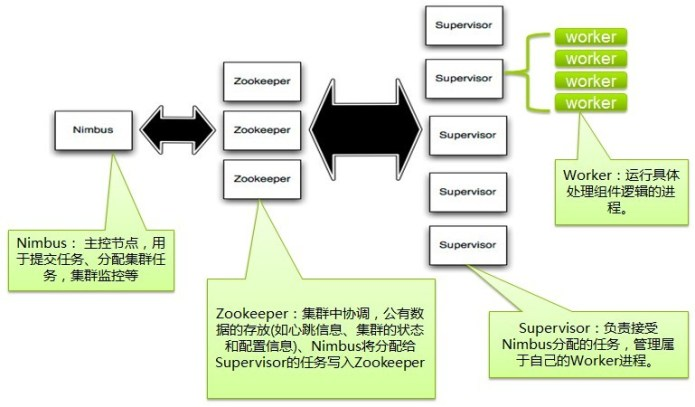
Apache Samza
Apache Samza是一种与Apache Kafka消息系统紧密绑定的流处理框架。虽然Kafka可用于很多流处理系统,但按照设计,Samza可以更好地发挥Kafka独特的架构优势和保障。该技术可通过Kafka提供容错、缓冲,以及状态存储。Samza是由LinkedIn开源的一个技术,它是一个开源的分布式流处理系统,非常类似于Storm。不同的是它运行在Hadoop之上,并且使用了自己开发的Kafka分布式消息处理系统。这是Linkin开发的一个小而美的项目,只有几千行代码,完成的功能就可以和Storm媲美。
Kafka Stream
Kafka Stream是一个轻量级的库。它对于来自Kafka的流数据,进行转换然后发送回kafka非常有用。我们可以将它看作类似于Java Executor服务线程池的库,却内置了对Kafka的支持。它可以与任何应用程序很好地集成,并且可以开箱即用。
由于其重量轻,可用于微服务类型的架构。在与Flink的性能方面没有匹配,但同时不需要单独的集群运行,非常方便,非常快速,易于部署和开始工作。根据相关应用程序的性质,无论是分布式节点还是单个节点,Kafka Streams都能支持。KafkaStream详解
Apache Spark
Apache Spark是一种包含流处理能力的下一代批处理框架。与Hadoop的MapReduce引擎基于各种相同原则开发而来的Spark主要侧重于通过完善的内存计算和处理优化机制加快批处理工作负载的运行速度。详解,链接
Apache Flink
Apache Flink是一种可以处理批处理任务的流处理框架。该技术可将批处理数据视作具备有限边界的数据流,借此将批处理任务作为流处理的子集加以处理。为所有处理任务采取流处理为先的方法会产生一系列有趣的副作用。之后我的一篇博客中会详解,链接
这种流处理为先的方法也叫做Kappa架构,与之相对的是更加被广为人知的Lambda架构(该架构中使用批处理作为主要处理方法,使用流作为补充并提供早期未经提炼的结果)。Kappa架构中会对一切进行流处理,借此对模型进行简化,而这一切是在最近流处理引擎逐渐成熟后才可行的。
对比与思考
当时选技术框架的时候主要在四个框架中思考和对比,Storm,Kafka Streams,Spark和Flink,各有各字的优势,针对我要做的项目特点,最终选用了Flink,对比及思考如下
Storm和Flink之间的对比
Storm是流处理曾经的大哥大,技术成熟度高,Flink是近些年来流处理冉冉升起的一颗新星,逐渐被各大厂注意到,两者面向的场景非常相似,因此选用时除了特性的对比之外,性能的对比就显得尤为重要了,这里将会引用美团在17年底对storm和flink的性能测试文章来进行性能对比,原文,近两年flink社区非常火爆,性能上应该已有了进一步的提高。
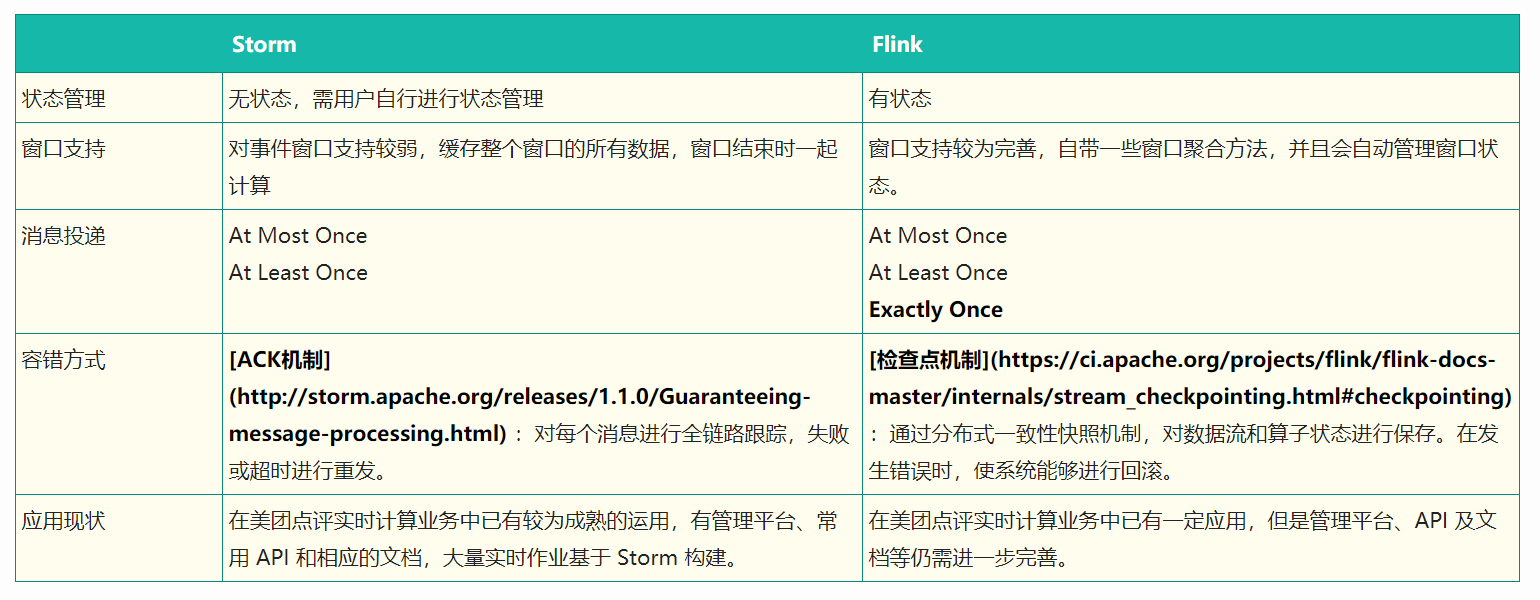
从特性来说,Flink有两点优势:
- 消息投递语义为 Exactly Once。Storm可能存在重复发送的情况,有很多业务场景对数据的精确性要求较高,希望消息投递不重不漏,Flink恰好一次的特性支持了此场景。
- 需要进行状态管理或窗口统计的场景,Flink 在窗口支持上的功能比 Storm 更加强大,API 更加完善,并且通过检查点机制,保存计算状态。
从性能上来看,Flink的吞吐量约为 Storm 的 3-5 倍。在数据量较大,要求高吞吐低延迟的场景中Flink更胜一筹。
Kafka Stream和Flink之间的对比
实时决策引擎是来自于我们导师接的一个智慧城市的项目,我们组有一个同学负责Kafka的那一部分,主要负责数据的采集和分发,我负责实时计算部分,还有一个同学负责冷启动的自适应异常检测(偏算法和离线分析),做Kafka的同学向我推荐了Kafka Stream来做实时计算。
Kafka Stream是基于Kafka的一个轻量级库,考虑到以下几点因素,没有选用他
- 如果在我们组同学开发的Kafka数据聚合分发模块中增加计算能力,必然会增加系统复杂度,不满足高内聚低耦合的设计原则
- 如果不在同组同学基础上进行开发,单独立项用Kafka Stream做流计算的话,数据源和数据去向的支持有限,API不如flink支持的丰富
- Kafka Stream轻量化、易部署,无需专门的集群,不像其他框架一样需要占用资源来部署,适合于资源有限或对易部署有要求的场景,而本项目主要针对于资源丰富的场景来考虑,因此不使用Kafka Stream。
Spark(Spark streaming)和Flink之间的对比
Spark Streaming 任务是基于微批处理的,其性能比不过以流式处理为主的flink,Spark和Flink都是既可以批处理又可以流处理的框架,但仍有不同Spark以批处理为主,Flink以流处理为主。
具体的详细对比参考博客Spark Streaming 和 Flink 详细对比